


【EP-18】用 n8n 打造科技資訊自動推送服務,順便聊聊如何學習
用 n8n 做自動化流程,每天早上 6 點,獲取指定關鍵字的英文新聞內容,再用 AI 翻譯成繁體中文,寄信到個人信箱。

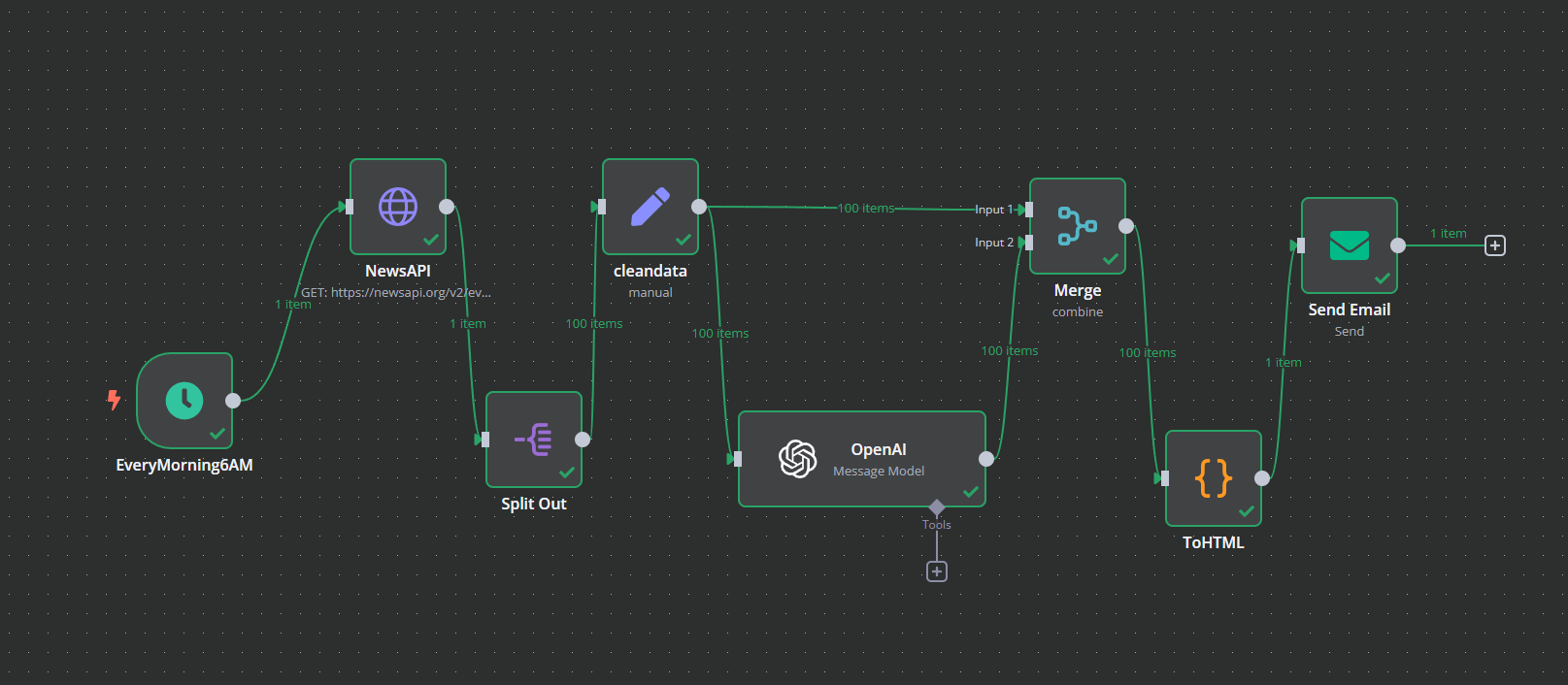
我做了在 n8n 上做了自動化流程,每天早上6點,從NewsAPI獲取前一日的科技新聞,使用大型語言模型翻譯後,再寄信到個人信箱。
因為我是菜雞,所以我摸索了快要6小時,含整理內容、寫文章,大約就要8小時。
可見 n8n 上手難度不易。
n8n 相比其他自動化平台,算是經濟又實惠了。n8n 本身開源,不用錢,而我部署在 Zeabur 上,每月基本費只要美金 5 元。假設你部署在家裡的電腦上,甚至可以免費。
但是就是難度頗高,令人生畏。
所以今天除了要介紹怎麼打造科技資訊自動推送服務,還要聊聊我是怎麼摸索學習 n8n 的。

1. 設定每日早上 6 點啟動流程
第一個節點,使用 Schedule Trigger。設定如下:
Trigger Interval:選擇 Days。
Days:1,因為每天都要做。
Trigger at Hour:選擇 6am。
Trigger at Minute:不用動。
這裡要注意系統時間,如果你是在你自己的電腦上架設的,可能還不需要調整系統時間。
但是我是在 Zeabur 上設定,系統預設時間是 UTC 時區,我身處台灣,必須使用 UTC + 8。
新增環境變數
進入「環境變數(Environment Variables)」設定
新增一個環境變數
Key:
TZValue:
Asia/Taipei
保存設定,然後重新啟動
n8n
2. 在 NewsAPI 取得最新新聞
為什麼要選擇 NewsAPI ,答案很簡單,身為免費仔,NewsAPI 可以讓我每天請求 100 次,不用花錢。
然後它也有名,所以資安方面稍微有一點保障。
第一步請先到 NewsAPI 註冊,網址:
https://newsapi.org/
註冊後就會馬上給你 API Key 。
接著在 Schedule Trigger 節點後面,加上 HTTP Request 節點,設定如下:
Method:Get
URL:NewsAPI 提供兩種選擇,一個是 everything ,一個是 top-headlines ,視自己的需求去設定,這部分可以閱讀 https://newsapi.org/docs/ 。看不懂英文可在瀏覽器上裝沉浸式翻譯。
我選擇 https://newsapi.org/v2/everything ,底下參數設定是基於此連結的,如果用top-headlines ,設定應該不太一樣,要查文件。
Send Query Parameters:打開。
Specify Query Parameters:選擇「Using Fields Below」,裡頭有 Name與 Value 的參數設定:
第 1 個參數(name:value),要設定前一天的日期。
from:{{new Date(Date.now() - 86400000).toISOString().slice(0, 10)}}
第 2 個參數,目的同上。
to:{{new Date(Date.now() - 86400000).toISOString().slice(0, 10)}}
第 3 個參數,設定關鍵字,我要找 AI、大型語言模型、SpaceX、機器人相關的新聞。
q:("AI" OR LLMs) OR "SpaceX" OR Robot
第 4 個參數,設定文章排序方式,我設定成先以日期為主。
sortBy:publishedAt
第 5 個參數,語言設定,我只搜尋英文新聞。
language:en
第 6 個參數,就是你剛剛註冊拿到的 API Key。
apiKey:你的 API Key
3. Split Out 節點
現在 NewsAPI 會回傳一個JSON物件,包含了 articles 陣列,格式像是這樣:
{
"status": "ok",
"totalResults": 778,
"articles": [ {新聞內容}, {新聞內容}, {新聞內容} ]
}
現在我們希望逐條處理這些資料,因此必須使用 Split Out 節點,設定如下:
Fields To Split Out:articles
Include:No Other Fields
現在我們就得到了一個純粹的陣列。
4. 使用 Edit Fields(Set) 節點整理資料
因為回傳的內容其實有一些我根本用不到,此時可以先用Edit Fields(Set) 節點初步整理,這裡我在節點上,特別把此節點取名為 cleandata 。設定如下:
Mode:Manual Mapping
Fields to Set:這裡可以用拖拉的方式,從左側的 Input 拉過來,我選擇了,
author
title
description
url
5. 使用 OpenAI 節點翻譯
這部分必須先到 OpenAI 取得 API Key ,不想用 OpenAI ,也可以用其他節點,如 Basic LLM Chain 或 AI Agent ,然後使用其他家的語言模型。
節點設定如下:
Resource:Text,當然是選文本
Operation:Message a Model
Model:GPT-3.5-TURBO,我覺得翻譯的話,這模型就夠用了,也比較便宜。
Messages:我使用兩個提示詞
System:給系統的提示詞如下,
你是一名專業的新聞翻譯助手,負責將英文新聞翻譯為繁體中文(台灣用語)。 請確保翻譯: 使用「手機」而不是「移動電話」 使用「軟體」而不是「軟件」 使用「影片」而不是「視頻」 保持翻譯流暢自然,適合台灣讀者 忠實於原文,不要擅自加字或刪減
User:當作使用者的提示詞,
請將以下新聞內容翻譯為繁體中文(台灣用語),保持專業新聞風格: 原文標題: {{$json["title"]}} 原文簡介: {{$json["description"]}}
如果你發現 {{$json["description"]}} 內容寫了類似 "Add your description here" ,就跳過此新聞內容。
你必須提供翻譯結果,格式如下, 標題: 摘要:
Output Content as JSON:打開,其實不打開也可以,但是我還是打開了,希望用 JSON 格式來做後續處理。
Options:這裡是指對於模型的進階設定,
Number of Completions:1,讓模型產生一個版本翻譯就好,避免浪費我的錢。
Output Randomness (Temperature)FixedExpression:0.4,要怎麼設定都可以,我是設定0.4,避免讓語言模型過度發揮創意。
這部分送出後,語言模型會逐條翻譯,最後送回翻譯結果,需要一點時間等待。
6. Merge 節點合併來自 cleandata 節點與 OpenAI 節點的資料
我現在把 cleandata 的部分資料送給語言模型翻譯了,但是某些資料我沒有送給它,例如 author 以及 url ,因此現在我們必須把兩份資料合併處理。
cleandata 節點的資料,我設定從 Input 1 進入。
OpenAI 節點的資料,我設定從 Input 2 進入。
不過從哪一個 Input 進入都沒關係,其餘設定如下:
Mode:Combine
Combine By:Position
Number of Inputs:2
7. 將資料轉成 HTML
現在我準備要寄信給我自己,但是在此之前,得先把資料轉成 HTML 格式,比較容易閱讀。
這裡用 Code 節點,寫一個簡單的 JavaScript 程式來轉換資料。
程式如下:
// 取得輸入的 JSON 資料
const items = $input.all();
let htmlContent = `
<html>
<head>
<style>
body { font-family: Arial, sans-serif; line-height: 1.6; }
.article { border-bottom: 1px solid #ddd; padding: 10px 0; }
.title { font-size: 18px; font-weight: bold; }
.translated-title { font-size: 16px; color: #007bff; }
.description, .translated-description { margin-top: 5px; }
.url { margin-top: 10px; font-size: 14px; }
</style>
</head>
<body>
<h2>昨日新聞</h2>
`;
items.forEach(item => { // 這裡要讓資料依序丟進去
const data = item.json;
const translated = data.message.content; // 翻譯後的內容
htmlContent += `
<div class="article">
<div class="translated-title">標題: ${translated["標題"]}</div>
<div class="title">Title: ${data.title}</div>
<div class="translated-description">摘要: ${translated["摘要"]}</div>
<div class="description">Description: ${data.description}</div>
<div class="url"><a href="${data.url}" target="_blank">閱讀更多</a></div>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
// 傳回 HTML 內容
return [{ json: { html: htmlContent } }];
8. 寄信
終於可以寄信了,請搜尋 Send Email 節點。
首先必須設定 SMTP account ,我是用 Gmail ,所以必須先取得應用程式密碼,不知道怎麼取得的人可以先讀這一篇文章:https://www.raven.tw/p/ep-17-zeabur-n8n
Gmail SMTP 設定

其餘設定:
Operation:Send
From Email:我的 Gmail 地址
To Email:我的 Gmail 地址
Subject:標題我是這樣寫,希望它帶入昨天的日期
From n8n: 昨日新聞摘要({{new Date(Date.now() - 86400000).toISOString().slice(0, 10)}})
Email Format:HTML
HTML:從左側 Input 拖曳過來,可能會是{{ $json.html }}
最後測試看看,成功之後,就可以在工作流上方按下 Active ,讓工作流每日寄信。
JSON 檔我放在 Google Drive ,有需要可以直接取用。
到底要怎樣學習 n8n
n8n 雖然是免費的,但是學習成本也比較高,我最常發生兩大問題:
不知道怎麼處理 JSON 格式資料
不知道 n8n 支援什麼 JavaScript 函式
遇到這類問題,我的方法就是直接問 ChatGPT ,例如在 Windows 環境下,按下 Shift + Windows + s 鍵,擷取特定區塊的圖片。再把圖片貼到 ChatGPT ,詢問 AI 如何設定。
這個方法很好用,解決了許多困難。
可是這麼做還是有個問題,畢竟 n8n 是會改版的,而 ChatGPT 不知道哪一個版本的知識才是正確的。
遇到這個情況,我會點擊節點設定頁面上的「Docs」,會直接連結到該節點的說明文件。你可以透過人工閱讀,也可以直接把連結丟給 ChatGPT 請他確認資訊。
不過我不建議在一開始就丟官方文件連結:https://docs.n8n.io/ ,給語言模型閱讀,因為它不會去讀底下的資料夾。
其實我認為更好的學習方式,應該是把最新版的 n8n 文件資料,做成 RAG 這種知識庫,讓 ChatGPT 回答時能夠依據知識庫的最新資料來回答。另外模型最好也是要採用最新版的,才能確保知識是最新的。
事實上,n8n 官方的確有一份最新資料在 Github 上可供下載,網址:https://github.com/n8n-io/n8n-docs
所以我之後應該會想辦法作一個 RAG ,才能夠加快製作工作流的時間。
你怎麼學習 n8n 的,有什麼好方法嗎?請留言讓我知道。
这太酷了!使用新闻 API apitube 源执行此操作